當我們在進行字義分析時可能會遇到一種狀況:
"This is a good movie." → :)
"This is a great movie." → :)
"This is a bad film." → :(
"This is a wonderful film." → ?
對於機器而言,在訓練集中它沒有見過wonderful,所以它沒辦法判別這個字的褒貶;而對於film,機器並不知道這是movie的相似字,在僅存的資料,它認為這個詞是貶義的。然而,這句話真實的意思應該是「這是一部很棒的影片。」應該賦予褒義。
為此,我們需要將語義包含到這樣的模型當中。我們可以運用「詞彙資料庫」(lexical database, e.g. Wordnet)中的語義資料和文字關係,將這些資訊放到這樣的模型中。
關於文字關係,可以參考:
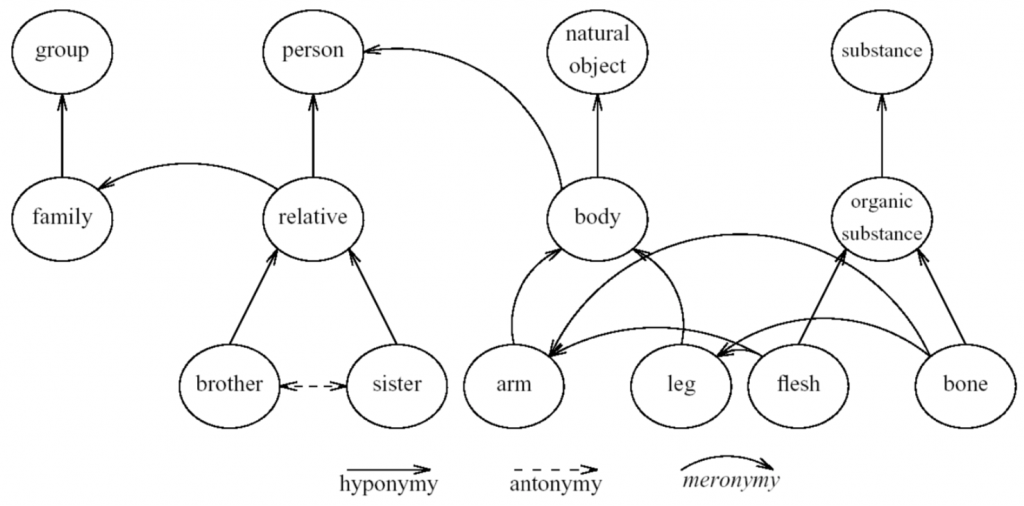
在Wordnet中的文字關係長得就像這樣:
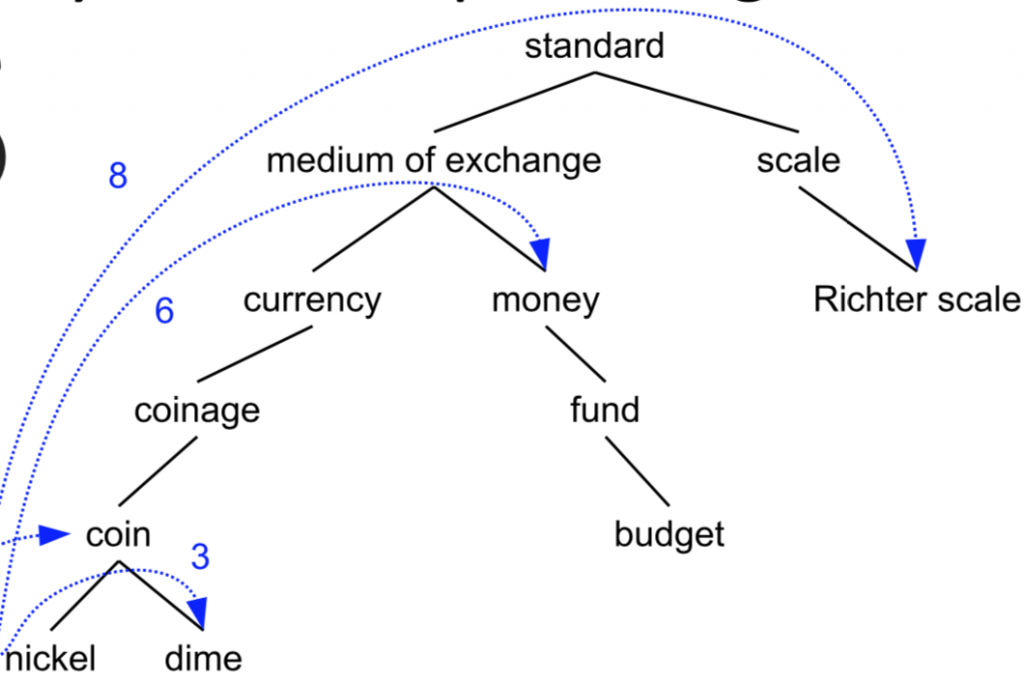
而要計算兩個詞在詞義關係上有多相似,我們可以用三種公式:
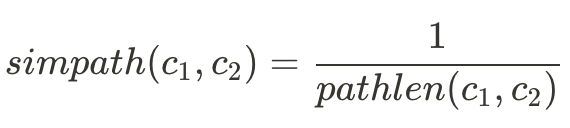
其中pathlen(c1,c2)是指兩字的距離。若c1=c2,則pathlen = 1。
例如:
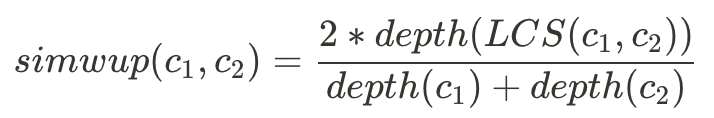
其中depth(c)是指字的深度,LCS(c1,c2)是lowest common subsumer,深度最低的相似字。
例如:
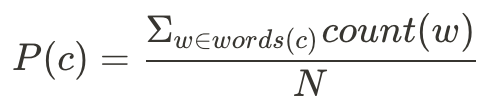
P(c)將所有包含這個字的文字(文字關係在c字之下的所有字,如P(coin)中的w={coin, nickel, dime}),N則為所有文集中的字數。

透過P(c)我們可以計算information content (IC):
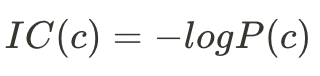
再透過IC計算Lin Similarity:
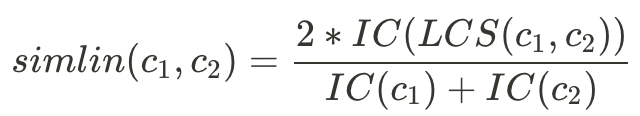
除了利用語言學中的語義關係,我們也可以用文字在文集中的分佈情形來計算文字相似度,例如知名的Word2Vec。

